关于Python中rank()函数的理解 |
您所在的位置:网站首页 › rank countif排名原理 › 关于Python中rank()函数的理解 |
关于Python中rank()函数的理解
|
刚开始学习《利用Python进行数据分析》这本书,当学习到对Serises和Dataframe进行排名的时候,有些疑惑,去网上搜索了很多关于这方面的解释,要么就是一两句带过,要么就是照搬书上的例子与结果,把我们这些刚入门的小白当成了高手,所以我打算自己认真的写一篇关于rank函数的简要解释说明。这是我第一次在CSDN上写博客,如果有不对的地方,可以留言,我会认真改正。页面做的很简单,望大家谅解。
Rank()函数
Rank也就是所说的”排名“,是指对数组从1到有效数据点总数分配名次的操作。 默认情况下,rank通过将平均排名分配到每个组来打破平级关系: 初始化一个序列 import pandas as pd obj = pd.Series([7,-5,7,4,2,0,4]) obj运行结果: 0 7 1 -5 2 7 3 4 4 2 5 0 6 4 dtype: int64 执行默认rank()操作 obj.rank()运行结果: 0 6.5 1 1.0 2 6.5 3 4.5 4 3.0 5 2.0 6 4.5 dtype: float64 运行结果分析: 元素索引排名-51#105#224#343#446#570#672#7根据上面的表格可以看出,索引0对应的元素排名为6,但是使用rank()会对排名求平均值,也就是说有N歌相同的元素,排名会相加并除以N,所以说索引0对应的元素最终排名为6.5;索引1对应的元素排名为1,所以它对应的排名值为1.0,以此类推得出上述运行结果。 rank(method=‘first’)这个函数其中传入了一个参数‘first’,作用是按照值在数据中出现的次序分配排名。 obj.rank(method='first')运行结果: 0 6.0 1 1.0 2 7.0 3 4.0 4 3.0 5 2.0 6 5.0 dtype: float64 运行结果分析: 元素索引排名-51#105#224#343#446#570#672#7结合上面的表格,我们拿索引为0的元素举例说明,可以看出索引0的排名为6,但是注意,当传入‘first’是就意味着不会对排名进行平均取值,所以即使有相同的元素,也会按照谁先出现就把谁排在前面(是不是有点像上学期间考试的成绩排名?按姓名字母排序,即使你俩分数一样)所以它对应的值为6.0,以此类推,在这里不再赘述。 rank(method = ‘max’)这里method的参数变为了 max,意味着对整个组使用最大排名。 obj.rank(method='max')运行结果: 0 7.0 1 1.0 2 7.0 3 5.0 4 3.0 5 2.0 6 5.0 dtype: float64 运行结果分析: 元素索引排名-51#105#224#343#446#570#672#7以索引为0的元素为例,它对应的元素是7,排名为6,但是它有一个和它一样的元素,排名为7,所以这里取最大的排名,也就是7,所以运行结果中索引为0对应的值为7.0,剩下的元素同理,这里不再赘述。 rank(method = ‘min’)min 的意思为对整个组使用最小排名。 obj.rank(method='min')运行结果: 0 6.0 1 1.0 2 6.0 3 4.0 4 3.0 5 2.0 6 4.0 dtype: float64 运行结果分析: 元素索引排名-51#105#224#343#446#570#672#7还是以索引为0的元素为例,它对应的值为7,排名为6,即使后面有和它值相同的元素,排名取它们其中最小的那个,所以运行结果中索引为0对应的值为6,其余元素以此类推,这里不再赘述。 rank(ascending = False, method = ‘max’)这个函数相较于上面的函数,多传入了一个ascending,它的意思是”升序“的意思,这里取值为 False,意为对元素进行降序排序;而且method的值取为 max,与上面的max作用相同。 obj.rank(ascending=False,method='max')运行结果: 0 2.0 1 7.0 2 2.0 3 4.0 4 5.0 5 6.0 6 4.0 dtype: float64 运行结果分析: 元素索引排名-51#705#624#543#346#470#172#2可以看出,与上面的表格相比,最大的变化是元素进行了降序排序,所以名次也发生了变化。我还是拿索引为0的元素拿来举例(因为它太有代表性了,所以我总是用它来说明),它现在对应的排名为6,但是这里method取的值为max,所以当有相同的元素时,取排名最大的那个,所以它的值为2.0,剩下的元素也是一样,这里不再赘述。 rank(ascending = False, method = ‘min’)这个函数相较于上面的函数,method的值变为了min,与上面的min作用相同。 obj.rank(ascending=False,method='min')运行结果: 0 1.0 1 7.0 2 1.0 3 3.0 4 5.0 5 6.0 6 3.0 dtype: float64 运行结果分析: 元素索引排名-51#705#624#543#346#470#172#2索引值为0的元素对应的排名为1,即使后面有相同的元素,取它们之中最小的排名,所以它对应的值为1.0,其余元素排名以此类推,这里不再赘述。 DataFrame.rank()它会对DataFrame的0轴进行排名(不了解轴的可以去看一下Numpy中ndarray的解释),可以把DataFrame理解为一个二维数组,对0轴排名也就是按着纵向排名 我们先初始化一个DataFrame frame = pd.DataFrame({'b' : [4.3, 7, -3, 2], 'a' : [0, 1, 0, 1],'c' : [-2, 5, 8, -2.5]}) frame运行结果: 运行结果: 这里传入了一个参数 axis,它的意思是"轴"的意思,上面的那个如果括号里不加,默认是对0轴进行排名(等价于axis=0),这个参数传入的值 columns 意为对‘b’,‘a’,'c’这几个列进行排名(横向排名)。 frame.rank(axis='columns')运行结果: 《利用Python进行数据分析》 |
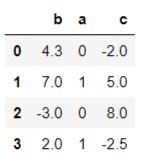
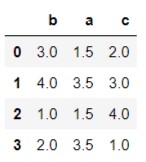 运行结果分析: 先对columns='b’的数据进行排名,然后对columns='a’排名,最后对column='c’进行排名,排名规则与上面的Series规则一致,这里不再赘述。
运行结果分析: 先对columns='b’的数据进行排名,然后对columns='a’排名,最后对column='c’进行排名,排名规则与上面的Series规则一致,这里不再赘述。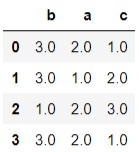 运行结果分析: 先对index=0这一行进行排名,其次对index=2排名,最后对index=3进行排名,排名规则也是和上面的一样。
运行结果分析: 先对index=0这一行进行排名,其次对index=2排名,最后对index=3进行排名,排名规则也是和上面的一样。【本文地址】
今日新闻 |
推荐新闻 |